Today we will take a look at a new issue that is related to Google Search Console, that is, is the crawl delay rule ignored by Google bot?, your site is no longer crawled after Google’s new updated policy.
We are facing a new problem when Google searches our website and uses robots.text from the website and based on that Google crawls our website but it is giving a message which is warning as follows – Rule is ignored by Googlebot
What is Crawl Delay?
The crawl delay directive for robot text file was introduced by other search engines in the early days. The idea was that webmasters could specify how many seconds the crawler would wait between requests to help limit the load on the web server.
Is the crawl delay rule ignored by Google Bot?
Yes, nowadays it turns out that servers are actually quite dynamic and it doesn’t really make sense to stick to the same period between requests. The value given there is the number of seconds between requests, which is not that useful anymore since most servers are capable of handling so much traffic per second.
Warning – Rule ignored by Googlebot
Solution:
If you also have this problem then follow these steps.
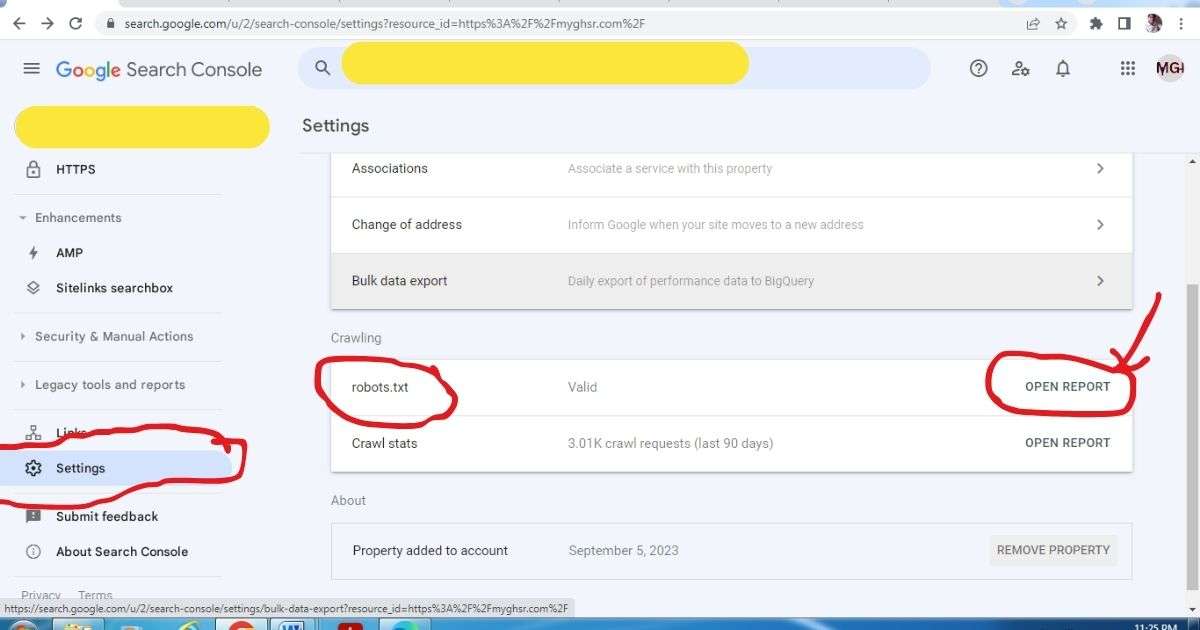
Step 1 – Go to your Google Search Console.
Step 2 – Go to your setting in Google Search Console and check right side panel there is robots.txt file available or not.
Step 3 – If robots.txt available the click on Open Report and check Status and Issue tab.
Step 4 – Go to your robots.txt file in your website’s master panel and remove Crawl-delay from it
Or
If you are using RankMath plugin then open robots.txt and remove crawl-delay from it.
Step 5 – Refresh the page
Is the crawl delay rule ignored by Google Bot?:
A great tool for testing robot text files is the Search Console, where we show this warning. What does it mean and what do you need to do? The crawl delay directive for robots.txt files was introduced by other search engines in the early days. The idea was that webmasters could specify how many seconds the crawler would wait between requests to help limit the load on the web server. Overall this is not a bad idea. However, it turns out that servers are actually quite dynamic and sticking to the same period of time between requests doesn’t really make sense. The value given there is the number of seconds between requests, which is not that useful anymore since most servers are capable of handling so much traffic per second. Instead of having a crawl delay directive, we decided to automatically adjust our crawling based on your server’s response. If we see server errors or we see the server slowing down, we will back off our crawling. Additionally, we have a way to provide feedback on your crawling directly in the Search Console.
Site owners can tell us about their preferred changes to crawling. With that said, if we see this instruction in your robot’s text file, we will try to tell you that it is something we do not support. Of course, if there are parts of your website that you don’t want crawled at all, it’s okay to let us know in the robot’s text file. See the documentation in the link below.
Help forum: https://support.google.com/webmasters…
Search Console: https://www.google.com/webmaster/tools
FAQ:
What is the crawl rate of Googlebot?
The crawl rate of Googlebot is how fast it looks at and reads web pages on the internet. Googlebot reads a lot of pages every second.
Is Googlebot a crawler?
Yes, Googlebot is a crawler. A crawler is a program that goes through the internet and reads web pages to understand what’s on them. Googlebot is Google’s crawler.
What is the limit of Googlebot crawler?
Googlebot doesn’t have a specific limit for all websites. It reads pages based on how important and relevant they are. Popular and important pages get crawled more often.
How do I stop Googlebot from crawling my website?
To stop Googlebot from looking at your website, you can use a file called “robots.txt.” It’s like a sign that tells Googlebot which parts of your site it can and can’t read.
What is the difference between Googlebot and crawler?
Googlebot is a specific crawler made by Google. A crawler is a general term for any program that reads web pages. So, Googlebot is a type of crawler made by Google.
How does Googlebot crawl?
Googlebot crawls by following links. It starts from a few known pages and then goes to other pages by clicking on links. It reads the content on these pages and uses that information to understand and index the web.
Also Read: Google Passkey: How To Set Up A Passkey For Google